Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

O que exatamente é Big Data ?
Para realmente entender o Big Data, é interessante analisarmos o histórico deste termo. Aqui está a definição do Gartner de 2001 (que ainda é a definição definitiva):
O Big Data é um grande volume de informações processados em alta velocidade e/ou ativos de informações com alta variedade, que exigem formas inovadoras e econômicas de processamento de informações, permitindo uma melhor percepção, tomada de decisões e automação de processos.
Simplificando, o Big Data é um conjunto grande e complexo de dados, esses conjuntos são tão volumosos que os softwares tradicionais de processamento de dados simplesmente não conseguem gerenciá-los. Mas esses enormes volumes de dados podem ser usados para resolver problemas de negócios que você não teria conseguido resolver antes.
Hoje, o big data, literalmente falando já significa capital (dinheiro). Pense em algumas das maiores empresas de tecnologia do mundo. Por que elas tem tanto valor de mercado?
Uma grande parte do valor que eles oferecem vem de seus dados, os quais eles estão constantemente analisando para produzir de forma mais eficiente e desenvolver novos produtos.
Recentes avanços tecnológicos reduziram exponencialmente o custo de armazenamento e computação de dados, tornando mais fácil e menos dispendioso armazenar mais e mais dados. Com um volume maior de big data, mais barato e mais acessível, você pode tomar decisões de negócios muito mais precisas.
Mas entenda que big data não é apenas análise, é um processo completo que exige analistas perspicazes e executivos que fazem as perguntas certas, reconhecem padrões, fazem suposições e preveem comportamentos.
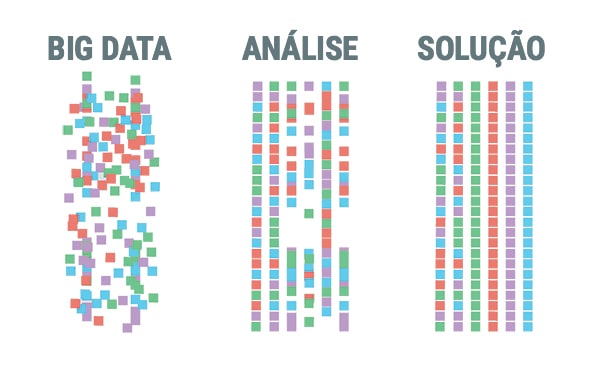
Embora o conceito de big data em si seja relativamente novo, as origens de grandes conjuntos de dados remontam às décadas de 1960 e 1970, quando o mundo dos dados estava apenas começando, com os primeiros datacenters e o desenvolvimento do banco de dados relacional.
Por volta de 2005, as pessoas começaram a perceber o quanto os usuários de dados geravam valor, através do Facebook, YouTube e outros serviços online. O Hadoop, uma estrutura de código aberto criada especificamente para armazenar e analisar grandes conjuntos de dados foi desenvolvido no mesmo ano. O NoSQL também começou a ganhar popularidade durante esse período.
O desenvolvimento de frameworks de código aberto, como o Hadoop e mais recentemente o Spark) foi essencial para o crescimento de Big Data, porque eles facilitam o trabalho com o armazenamento e custo mais barato.
Nos anos desde então, o volume de big data disparou, os usuários ainda estão gerando grandes quantidades de dados, mas não são apenas os humanos que estão fazendo isso.
Com o advento da Internet of Things (IoT), mais objetos e dispositivos estão conectados à Internet, reunindo dados sobre padrões de uso do cliente e desempenho do produto. O surgimento do aprendizado de máquina produziu ainda mais dados.
A Bolsa de Nova York gera cerca de um terabyte de novos dados comerciais por dia.

As estatísticas mostram que 500 terabytes de novos dados são inseridos nos bancos de dados do Facebook todos os dias. Esses dados são gerados principalmente por uploads de fotos, vídeos, mensagens, comentários etc.

A Single Jet pode gerar 10 terabytes de dados durante 30 minutos de um vôo. Com muitos milhares de vôos por dia, a geração de dados chega a muitos petabytes .

Big data pode ser encontrado em três formas:
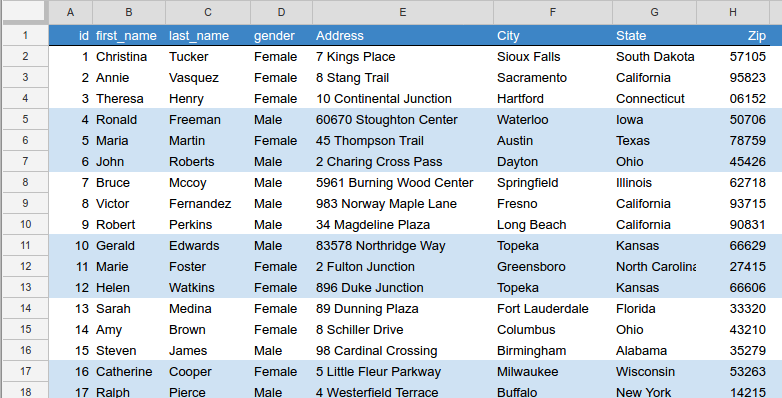
Quaisquer dados que possam ser armazenados, acessados e processados em formato fixo são denominados dados “estruturados”. Ao longo do tempo foram desenvolvidas técnicas para trabalhar com esse tipo de dados e também extrair valor disso.
No entanto, hoje em dia há previsão de problemas quanto ao tamanho de tais dados que estão crescendo em grande escala, os tamanhos já estão na faixa de vários Zettabytes (medida de armazenamento que corresponde a 2^70 bytes. Equivale a 1.024 Exabytes, 1.048.576 Petabytes, 1.073.741.800 Terabytes ou, para ser exato, 1,180,591,620,717,411,303,424 bytes).
Um banco de dados ou um planilha são exemplos de dados estruturados:
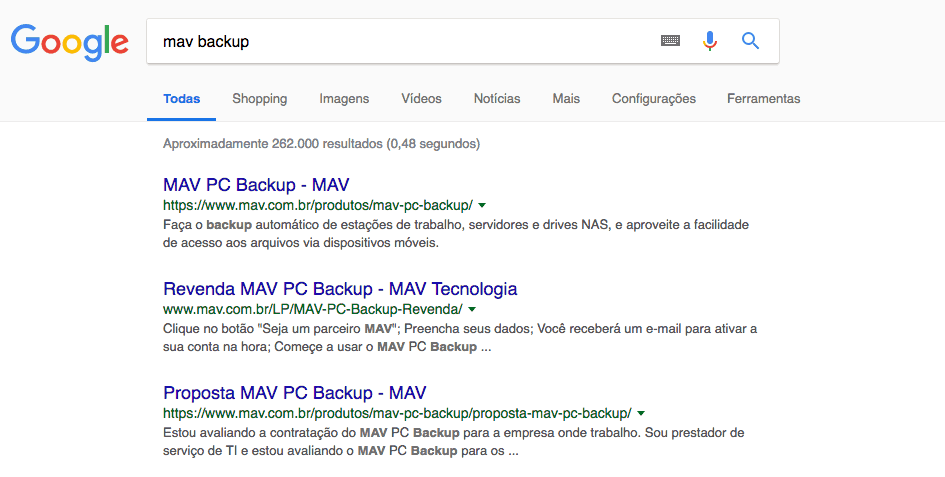
Quaisquer dados com formato desconhecido ou sem estrutura são classificados como dados não estruturados. Além do tamanho ser enorme, dados não estruturados apresentam múltiplos desafios em termos de processamento, tornando muito difícil obter valor a partir deles.
Um exemplo típico de dados não estruturados é uma fonte de dados heterogênea contendo uma combinação de arquivos de texto simples, imagens, vídeos, etc., assim como a saída retornada de uma pesquisa do Google:
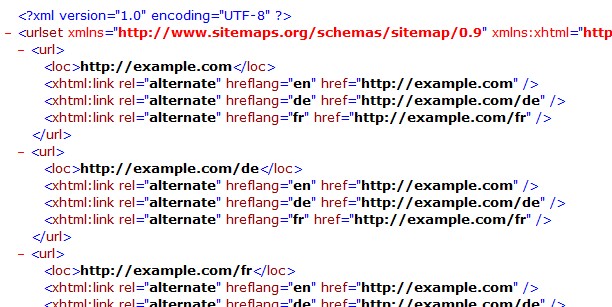
Dados semi-estruturados podem conter as duas formas de dados. Podemos ser dados semi-estruturados como um formato estruturado, mas entanto não é definido como uma tabela ou banco de dados por exemplo. Talvez fique mais fácil de entender com um exemplo, como este arquivo XML:
A capacidade de processar grandes quantidades de dados traz vários benefícios, como:
Embora o Big Data tenha muitos benefícios, também tem seus desafios.
Em primeiro lugar, Big Data é algo muito, muito grande e embora tenham sido desenvolvidas novas tecnologias para armazenamento de dados, os volumes de dados estão dobrando de tamanho a cada dois anos.
As organizações ainda lutam para acompanhar este crescimento das informações e encontrar formas de armazená-las de maneira eficaz.
Mas não é suficiente apenas armazenar os dados, pois para os dados terem valor dependem de uma curadoria, ou seja dados limpos e relevantes para o cliente, organizados de uma maneira que possibilite uma análise significativa.
Isso exige muito trabalho, os cientistas de dados gastam de 50 a 80% do tempo curando e preparando os dados antes que possam ser usados.
Por fim, a tecnologia de Big Data está mudando em ritmo acelerado. Há alguns anos, o Apache Hadoop era a tecnologia mais popular para manipular grandes volumes de dados, em seguida o surgiu Apache Spark (2014).
Hoje, uma combinação dos dois frameworks parece ser a melhor abordagem, porém manter-se atualizado com a tecnologia de Big Data é um desafio contínuo.
Você não deve se impressionar com todo modismo que surge, não é por que uma tecnologia está sedo usada por algumas empresas que necessariamente é útil para você e seu negócio.
Dependendo o seu negócio, big data vai somente fazer você perder tempo e dinheiro, pois podem existir outros pontos de atenção na sua empresa que farão muito mais diferença trazendo mais resultados.
Empresas que se dão bem com big data, normalmente são empresas maduras e com uma cultura de investir e realmente usar tecnologia. Se a sua empresa não tem esta cultura, não é o momento para você investir nisso.
Não fique para trás, acompanhe nosso blog e entenda como a Tecnologia pode alavancar seu negócio!
PS: Não esqueça de dar uma olhada no nosso livro sobre Carreira de TI. Um abraço!




[…] Simplificando, o Big Data é um conjunto grande e complexo de dados, esses conjuntos são tão volumosos que os softwares tradicionais de processamento de dados simplesmente não conseguem gerenciá-los. Saiba mais… […]